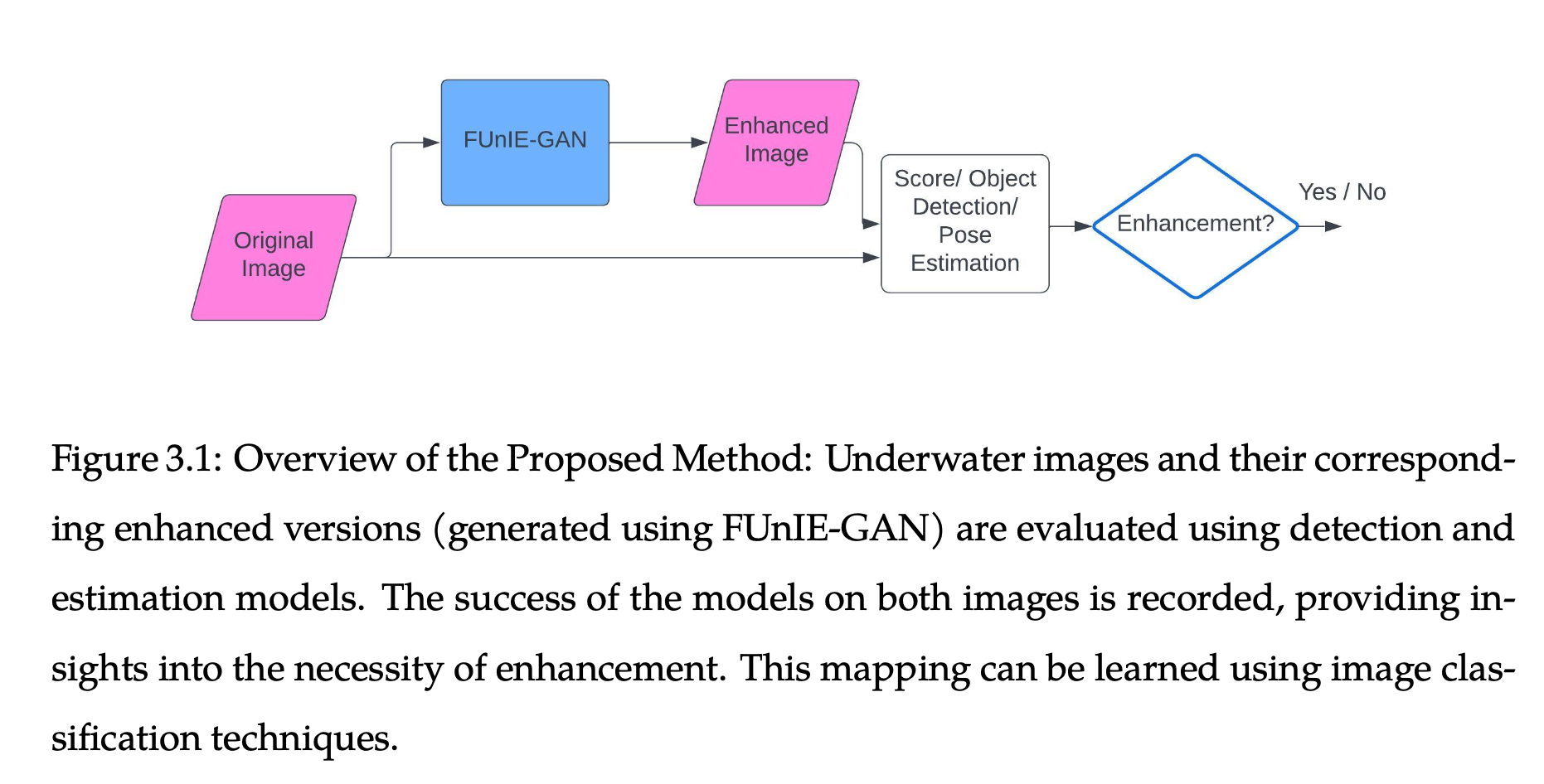
Utility of Image Enhancement For Underwater Tasks: GAN, YOLOv8, Siamese Network
Recently, learning-based image enhancement methods have demonstrated promising performance in underwater conditions. However, these models often come with a high computational cost. In this study, we aim to evaluate the relevance of image enhancement based on the specific task at hand. Additionally, we strive to develop a predictive method to determine whether image enhancement is necessary. Enhanced images were generated using ’Fast Underwater Image Enhancement for Improved Visual Perception’ (FUnIE- GAN) [1] and were evaluated quantitatively and visually. Further, bounding boxes were predicted using object detection models for both original and enhanced images. These predictions were analyzed and binary labels were created for the images to predict the necessity of image enhancement for the task. Despite our efforts, we have encountered challenges in devising an effective predictive method due to the limitations of the training set. This idea does show promise for further exploration with a specialized dataset to train all the models involved.
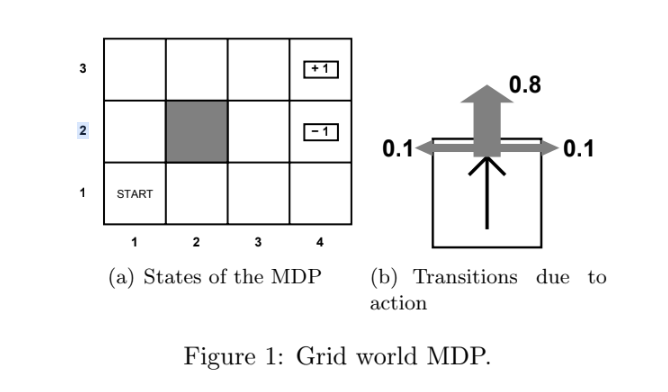
Comparison of Reinforcement Learning Algorithms: Python, Dynamic Programming
Recently, learning-based image enhancement methods have demonstrated promising performance in underwater conditions. However, these models often come with a high computational cost. In this study, we aim to evaluate the relevance of image enhancement based on the specific task at hand. Additionally, we strive to develop a predictive method to determine whether image enhancement is necessary. Enhanced images were generated using ’Fast Underwater Image Enhancement for Improved Visual Perception’ (FUnIE- GAN) [1] and were evaluated quantitatively and visually. Further, bounding boxes were predicted using object detection models for both original and enhanced images. These predictions were analyzed and binary labels were created for the images to predict the necessity of image enhancement for the task. Despite our efforts, we have encountered challenges in devising an effective predictive method due to the limitations of the training set. This idea does show promise for further exploration with a specialized dataset to train all the models involved.

3D Semantic Reconstruction: PyTorch, Scikit-Learn, UNet, COLMAP, kNN Classifier
In this project, we conducted a 3D reconstruction of an environment while preserving the semantic information. We constructed a pipeline from 2D semantic labels and 3D reconstructed points to estimate 3D semantic reconstruction. Our methodology involves the generation of 3D sparse and dense point clouds using COLMAP, extraction of the segmentation masks using U-Net from the images provided, and finally employing a voting mechanism paired with a k-means algorithm to perform 3d semantic reconstruction.

Off-road Driveable Area Segmentation: PyTorch, CycleGAN
In our project, we plan to employ CycleGAN as a pivotal tool for generating ground truth labels due to its unique ability to address the challenges associated with off-road data. CycleGAN facilitates the creation of synthetic off-road images and corresponding segmentation masks, effectively expanding the available dataset without the need for extensive manual labelling. By leveraging CycleGAN, we not only alleviate data scarcity issues but also enhance domain adaptation, making the segmentation model more robust to variations in off-road environments. This approach contributes to more costeffective and efficient data generation. It allows us to tackle the scarcity of labelled off-road data while ensuring the model’s capacity to perform effectively in a wide range of off-road scenarios.
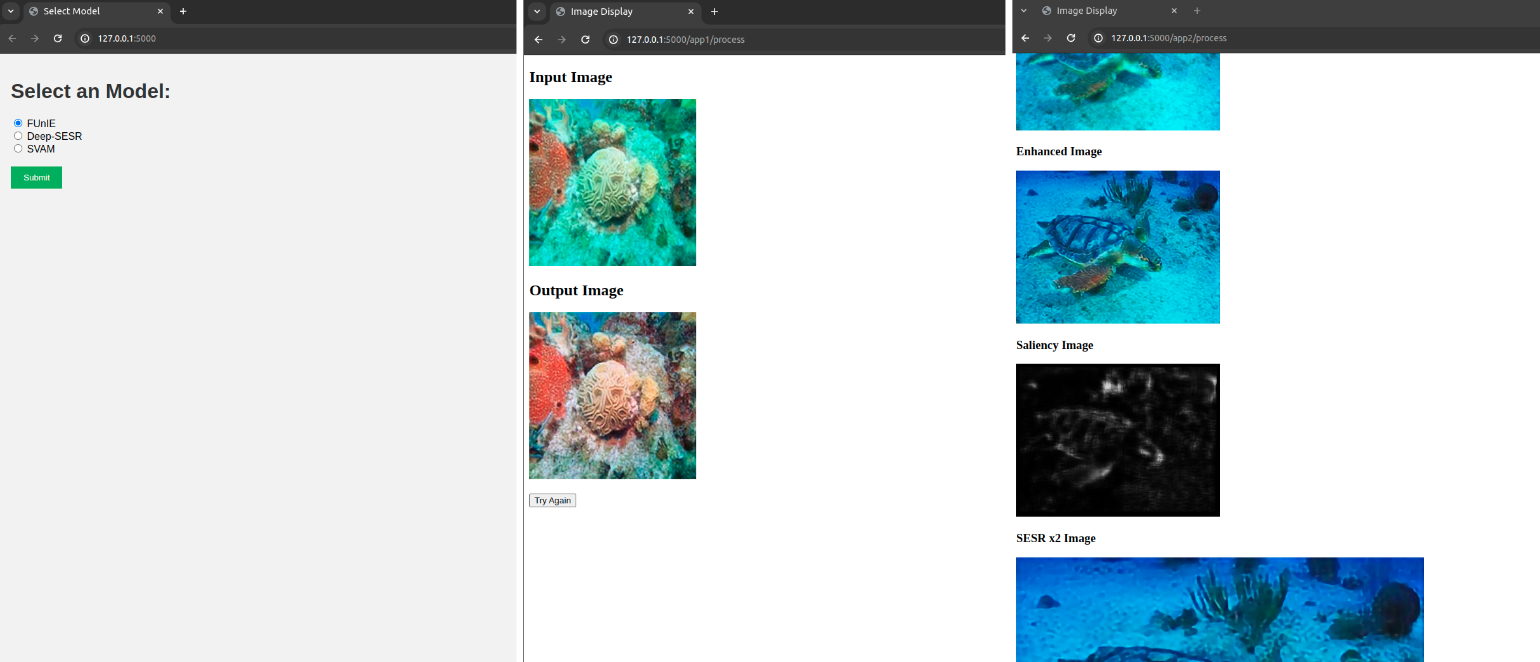
Web App for FUnIE-GAN, Deep-SESR, SVAM: Python, flask, HTML, and CSS
The image enhancement models often tend to have an overwhelming code base and is hard for people from other domains to access these models. For convenience and increased usage by people who want to use them for research and other applications, We have developed a flask-based app to easily interact with these models through the web and get the output. This lays down a platform to easily analyze the outputs of the model for future work.
Box Sorting using Baxter Robot: Robot Operating System (ROS), OpenCV, Computer Vision
Robots have the potential to benefit us by increasing efficiency, reducing labour-intensive tasks, and allowing humans to focus on more complex and higher-value activities. Sorting objects at a large scale is an excellent example of this. In this project, we use Rethink Robotics’ Baxter robot with ROS and OpenCV to identify and sort boxes. We use object detection with colour recognition and inverse kinematics to accurately move the boxes. We achieved our goal of sorting and stacking cubes of three different colours. The work can be further extended to objects of multiple shapes and sizes.
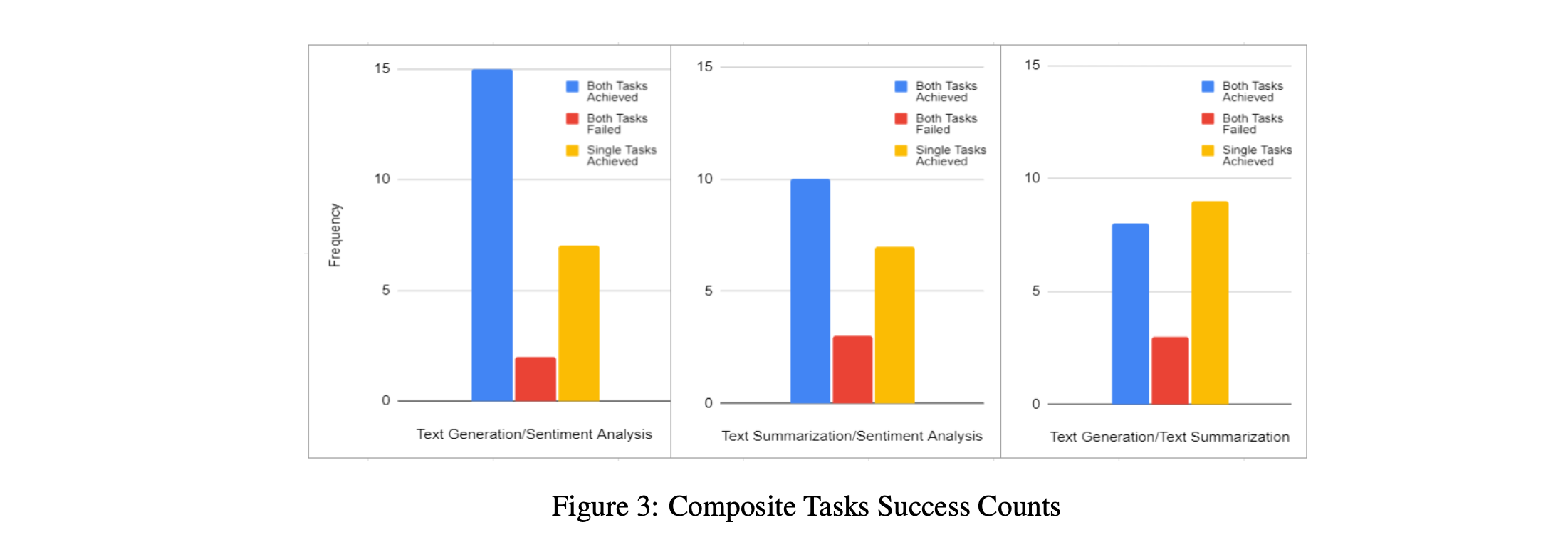
Generalizability of FLAN-T5 Model Using Composite Task Prompting: Hugging Face, LLM, NLP
This project aims to contribute to the field of natural language processing by evaluating the effectiveness of a widely used model "google/flan-t5" and exploring its potential for handling multiple tasks. We hope that the findings of this study will provide valuable insights and pave the way for further research in this area.

Mobile Robot Path Planning in Diverse Terrain Environments: Python, A*, D*, RRT
Effective path planning is a crucial skill that these robots must possess to detect and make decisions based on various obstacles and topographical perturbations. In this project, two simple planning problems will be posed. The first problem will include robot path planning in an environment with only obstacles. This environment will be used to compare some more advanced pathplanning algorithms that build off of algorithms covered in class. The second problem will be determining an efficient method for path planning in an obstructed and uneven environment. Only A* will be used in this scenario and the diverse terrain will be represented by a custom cost map. Results from these two problems will highlight the advantages and disadvantages of more advanced search algorithms, and provide preliminary results for their operation in diverse terrain environments.

Comparative Study of Machine Learning Algorithms on Sentiment Analysis of Product Reviews: Python, scikit-learn, Tensorflow
For a very long time, making a machine understand the natural language and process it to perform a creative task has been a problem of high priority to human. Classifying whether a product being sold is worth buying makes it easier for the buyer to make his decision. This also helps the seller to analyse his sales. In this paper, we have done a comparative analysis of different machine learning algorithms and studied how well each algorithm works in classifying human sentiments from natural language in text based product reviews.
Published in 4th International Conference on Information and Communication Technology for Competitive Strategies (ICTCS 2019), December 13th-14th, 2019.

An Ensemble Approach to Hostility Detection in Hindi Tweets: Python, Transfer Learning, NLP
In today’s world, social media platforms are prevalent in all walks of life. However, the content on these platforms is often created with hostile intent. With the increase of such hostile content in social media, there has arisen a need to effectively detect such posts so as take appropriate measures against them. Hence, extensive studies have been performed in this field for the English language, however, similar work is relatively sparse in the case of Indian languages like Hindi. The work done here introduces a transfer learning-based approach with an ensemble model on top for identifying and flagging posts of hostile intent on social media platforms written in the Hindi Devanagari script. For this purpose, we have leveraged the pre-trained Fasttext model trained on Hindi text. Our model achieves F1-scores of 76% on the Defamation class, 80% on the Fake class, 69% on the Hate class and 79% on the Offensive class on the provided test set.
Published in 7th IFIP International Conference on Computer, Communication and Signal Processing, (ICCCSP 2023) January 4 – 6, 2023.